Data Science Articles
What Is Correlation in Data Science? A Guide for Beginners
What is Data Wrangling? Key Steps & Benefits


Get In Touch For Details! Request More Information

A Comprehensive Guide to Data Modeling in MongoDB [2024]
May 20, 2024 6 Min Read 1045 Views
(Last Updated)
If we take the famous quote “With Great Power, comes Great Responsibility”, and change its context according to the current tech world, we’ll have “With Great Innovations, comes Great Data”.
So, data is now an integral part of our life and the field of data science is booming like anything as the world needs more people to manage the data by using software like MongoDB. Combining both data modeling and MongoDB, we have a concept called data modeling in MongoDB.
In this article, you will learn everything related to data modeling in MongoDB along with its definition, its key concepts, its techniques, and so on. By the end, you will be equipped with a greater knowledge to efficiently story greater data.
So, without further ado, let’s get started:
Table of contents
- Understanding Data Modeling in MongoDB: An Easy Explanation
- What is Data Modeling?
- Why is Data Modeling Important?
- Key Components of Data Modeling in MongoDB
- Key Concepts of Data Modeling in MongoDB
- Embedding vs. Referencing
- Schema Design Patterns
- Indexes
- Normalization and Denormalization
- Best Practices for Effective Data Modeling in MongoDB
- Understand Your Application's Data Access Patterns
- Optimize for Performance
- Ensure Scalability
- Plan for Data Consistency
- Regularly Review and Refine Your Data Model
- Advanced Techniques for Data Modeling in MongoDB
- Handling Large Arrays
- Utilizing Transactions
- Index Management
- Consider Shard Key Selection Carefully
- Conclusion
- FAQs
- How does a collection in MongoDB differ from a table in SQL databases?
- Can you explain the concept of shard keys?
- When should I use embedding over referencing in MongoDB?
- How can I manage large arrays of data without affecting performance?
Understanding Data Modeling in MongoDB: An Easy Explanation
Let’s dive a bit deeper into what data modeling in MongoDB is and why it’s essential, especially if you’re just starting out or coming from a background in traditional relational databases.
What is Data Modeling?
To put it simply, data modeling in MongoDB is about organizing and structuring the data in your database. Since MongoDB is a NoSQL database, it does things a bit differently from what you might be used to with SQL databases.
Instead of tables, MongoDB uses what are called collections, and instead of rows, it stores documents. These documents are similar to JSON objects, which are flexible and can contain varied structures within the same collection.
Also Read: 15 Most Common SQL Queries with Examples
Why is Data Modeling Important?
Data modeling is important because it directly impacts the performance, scalability, and manageability of your database.
A well-thought-out data model helps you efficiently store and access your data, which can lead to better performance of your application. It also makes your database easier to scale and maintain over time.
Key Components of Data Modeling in MongoDB
When you’re planning for data modeling in MongoDB, you’ll primarily work with:
- Documents: These are the core elements where data is stored in MongoDB. Think of them as individual records or objects. Each document can have a different structure with various fields.
- Collections: Collections are like folders that hold your documents. They are analogous to tables in relational databases, but unlike tables, they do not enforce a uniform structure across documents.
- Fields: Fields are similar to columns in an SQL table. However, because MongoDB is schema-less, different documents in the same collection can have different fields.
Understanding data modeling in MongoDB is about grasping how documents, collections, and fields work together.
Read More: MongoDB vs. MySQL: Which Database Should You Learn?
Key Concepts of Data Modeling in MongoDB
When you’re starting your journey of data modeling in MongoDB, there are a few key concepts that you’ll need to understand to make effective use of its capabilities.
But before that, make sure you are thorough with the basics of data science. If not, consider enrolling for a professionally certified online Data Science course that would help you strengthen your basics along with an industry-grade certificate.
Let’s break down the concepts needed for data modeling in MongoDB:

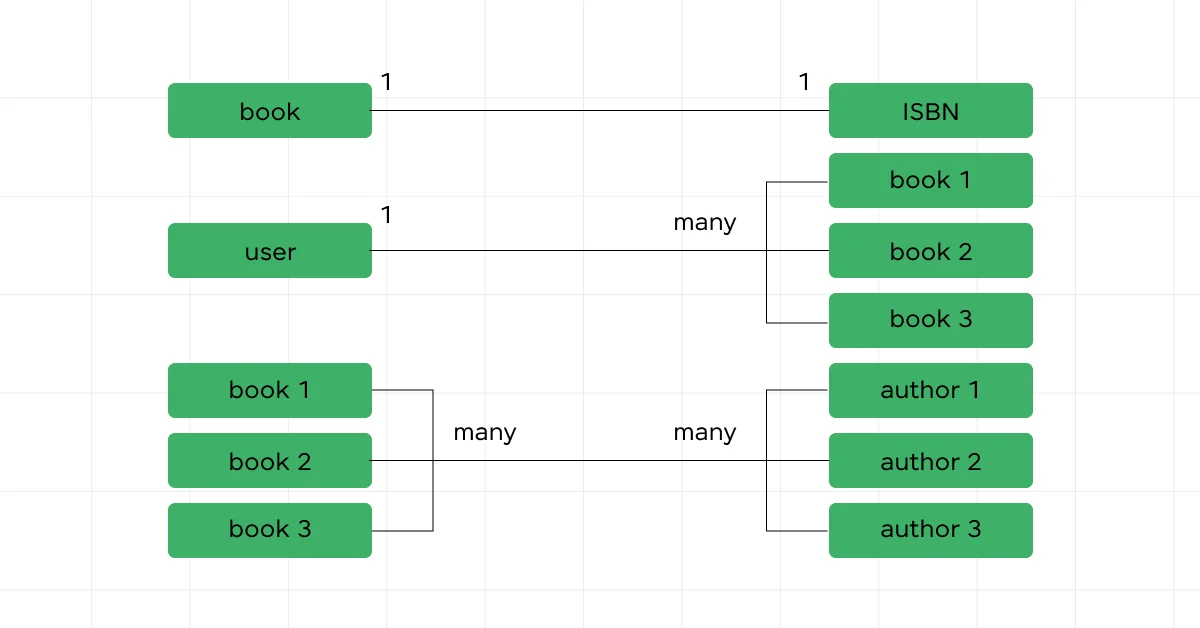
1. Embedding vs. Referencing
These two terms describe how you can organize related data in your MongoDB database. Deciding between embedding and referencing is like choosing between keeping all your related items in one big bag (embedding) or having several smaller bags linked with tags (referencing).
- Embedding: Imagine you’re building an app for a bookstore. Each book might have information like title, author, and genre, and also a list of reviews. If you embed the reviews directly within each book’s document, everything about the book is in one place.
- Referencing: Now, consider that some reviews are very detailed and are shared across different books by the same author. Instead of embedding these large, shared reviews in every book document, you could reference them. You do this by storing the reviews in their own collection and including a reference (like an ID) in the book documents.
Also Read: Best Way to Learn Data Science in 2024
2. Schema Design Patterns
Even though MongoDB is schema-less, which means documents in the same collection don’t need to follow the same structure, there are still common patterns that can help you design your schema in data modeling in MongoDB efficiently:
- The Attribute Pattern: Useful when your documents might have many different attributes that only apply to some of the data. For example, in a product catalog, some items might have warranties while others don’t.
- The Bucket Pattern: This is great for handling situations where you have large arrays or lists of items, like logs or time-series data. Instead of adding each new item as a separate document, you “bucket” multiple items into a single document. Think of it like a bucket where you throw in all the logs for an hour or a day instead of having a single log per document.
- The Polymorphic Pattern: This pattern comes in handy when documents in a collection are related but have different forms. A simple example would be a collection of media, which could include books, movies, and music albums. Each type of media shares common fields like title and genre, but also has unique fields like author (books), director (movies), or artist (music).
Know More: Best Mongo DB Course Online with Certification
3. Indexes
Indexes in data modeling in MongoDB are like the index in a book. They help you find information quickly without having to look through every page (or document).
Creating indexes on the fields that you query often greatly improves your query performance. However, every index you add also takes up space and can slow down how quickly you can write new data, so it’s important to balance the number of indexes with the needs of your application.
4. Normalization and Denormalization
These terms are borrowed from relational database management systems, but they’re also applicable in data modeling in MongoDB:
- Normalization: This involves separating data to eliminate redundancy. For example, storing user profiles in one collection and references to their posts in another collection. It helps reduce data duplication but can require more references and potentially more complex queries.
- Denormalization: This involves combining data to reduce the number of queries. For example, storing user comments directly within a blog post document.
Understanding these key concepts of data modeling in MongoDB will help you make informed decisions about how to structure your data in MongoDB.
This adaptive approach is a powerful advantage of using MongoDB, so take full advantage of it!
Learn More: Top 7 Reasons To Learn MongoDB!
Best Practices for Effective Data Modeling in MongoDB
When you’re setting up or refining your database in MongoDB, it’s important to follow some best practices for data modeling in MongoDB to ensure that your data model is both efficient and scalable.
Here’s how you can effectively practice data modeling in MongoDB:
1. Understand Your Application’s Data Access Patterns
One of the first things you should do is really understand how your application will interact with the data. Ask yourself:
- What kind of data are you storing?
- How often will you need to access this data?
- What are the most common queries you will run?
- Will your data access needs change over time?
For example, suppose you’re building an e-commerce application. In that case, you’ll likely need to access product information very frequently, so you should design your database to make this as efficient as possible.
Understanding these patterns helps you decide how to structure your data, what indexes to create, and whether to use embedding or referencing for data modeling in MongoDB.
Find Out How Long Would It Take to Learn Data Science?
2. Optimize for Performance
Performance optimization is key in data modeling in MongoDB. Here are a few ways you can optimize MongoDB:
- Indexing: As mentioned before, indexes are like the index in a book—they help MongoDB find data without scanning every document. Create indexes on fields that are frequently used in queries. However, keep in mind that each index adds overhead to your database operations, especially when writing data.
- Balancing Embedding and Referencing: Choose wisely between embedding and referencing based on your use cases. Embed related information that you often access together to reduce the number of queries.
3. Ensure Scalability
Scalability is about how well your database can grow to meet increased demand. Here are some tips to ensure that your MongoDB setup is scalable:
- Sharding: MongoDB can distribute data across multiple servers using sharding. This approach helps manage large data sets and high throughput operations by partitioning data across several machines. Choose a shard key that evenly distributes your data to avoid bottlenecks.
- Replication: Use MongoDB’s built-in replication features to ensure high availability and data durability. Replication involves maintaining copies of your data on multiple servers, so if one server goes down, others can take over.
Also, Know About A Complete Guide on Data Science Syllabus | 2024
4. Plan for Data Consistency
In a distributed database like MongoDB, managing data consistency is crucial. MongoDB offers different levels of consistency, so you need to choose the right balance between performance and consistency for your needs:
- Write Concerns: MongoDB allows you to specify how many copies of your data must confirm a write operation before it is considered successful. More stringent write concerns increase data safety but can impact performance.
- Read Concerns: These determine the consistency and isolation properties of the data read. Higher read concerns offer more up-to-date data but can reduce performance.
5. Regularly Review and Refine Your Data Model
Your application’s needs will evolve, and so should your data model. Regularly reviewing and refining your data model based on real-world use and performance metrics is essential.
This might mean changing your indexing strategy, adjusting how you use embedding versus referencing, or reevaluating your shard keys.
Remember that, effective data modeling in MongoDB is not a one-time task—it’s an ongoing process of adaptation and refinement. This proactive approach will help you make the most out of MongoDB’s powerful features and ensure that your application performs well as it grows.
Explore: Data Science vs Data Analytics | Best Career Choice in 2024
Advanced Techniques for Data Modeling in MongoDB
As you become more comfortable with data modeling in MongoDB and your application starts to scale, you might need to consider some advanced techniques to optimize performance, maintainability, and scalability.
Let’s explore some of these advanced strategies that can help you fine-tune your data modeling in MongoDB.
1. Handling Large Arrays
If you find yourself dealing with large arrays—like user comments on a social media post or inventory items in a warehouse management system—managing this data efficiently is crucial.
- Bucket Pattern: Instead of storing each item as a separate document, consider using the bucket pattern. This means grouping multiple items into a single document. For example, instead of a document for each comment, group comments by day or post.
- Pagination: When displaying large datasets, such as logs or comments, use pagination techniques to load data in chunks rather than all at once. This not only improves the load times but also enhances the user experience by not overwhelming them with too much data at once.
Also Read: How to Render an Array of Objects in React? [in 3 easy steps]
2. Utilizing Transactions
Data modeling in MongoDB supports multi-document transactions. This is useful when you need to perform multiple operations across different documents or collections and you want them all to succeed or fail as a unit.
- When to Use Transactions: Transactions are great for operations that need strong consistency, such as transferring money between bank accounts or updating multiple related documents where you can’t afford to have only some of the changes apply.
3. Index Management
Efficient management of indexes is critical as your application scales:
- Review and Optimize Indexes Regularly: As your data grows and access patterns change, some indexes might become less useful while others might become necessary.
- Covered Queries: Optimize queries to be “covered” by the indexes. This means all the fields needed for the query are in the index itself, allowing MongoDB to serve queries entirely from the index without having to look up the full documents.
Also Read About 12 Real-World Data Science Examples: Power Of Data Science
4. Consider Shard Key Selection Carefully
Sharding involves distributing your data across multiple servers. The choice of shard key is crucial because it determines how data is distributed:
- Choose High-Cardinality Fields: A good shard key has high cardinality, which means it has a large number of possible values. This helps evenly distribute data across shards.
- Consider Write and Read Performance: Think about how shard key choices affect performance. Keys that lead to uneven data distribution can create hotspots that degrade performance.
These techniques help you gain an edge over the concept of data modeling in MongoDB and helps you stand out in the field of data management.
If you want to learn more about data modeling in MongoDB, then consider enrolling in
GUVI’s Certified Data Science Career Program not only gives you theoretical knowledge but also practical knowledge with the help of real-world projects.
Also, Read Future of Data Science and How You Can Thrive With It.
Conclusion
In conclusion, data modeling in MongoDB offers a unique blend of flexibility and power, essential for managing modern application data efficiently.
By understanding and implementing key concepts such as embedding versus referencing, utilizing schema design patterns, and balancing de-normalization with normalization, you can optimize both performance and scalability.
MongoDB equips you with the tools to adjust your data environment precisely to your needs, ensuring robust and scalable applications.
Also, Find Out Top 10 High Paying Non-Coding Jobs in Data Science in 2024
FAQs
1. How does a collection in MongoDB differ from a table in SQL databases?
A collection in MongoDB is analogous to a table in relational databases but does not enforce a uniform structure across its documents. This means each document in a collection can have a different set of fields.
2. Can you explain the concept of shard keys?
Shard keys are used in sharded MongoDB clusters to distribute data across multiple machines. Choosing an appropriate shard key is vital for ensuring data is evenly distributed and query loads are balanced.
3. When should I use embedding over referencing in MongoDB?
Embedding should be used when data entities are accessed together frequently and the size of the embedded data is manageable, as it reduces the need for separate queries.
4. How can I manage large arrays of data without affecting performance?
Besides using the bucket pattern, implementing pagination to retrieve data in manageable chunks can also help manage large arrays without compromising performance.
Career transition






















Did you enjoy this article?